Elasticsearch
Table of Contents
Reference
APIs
<index>
bulk
- Every line must end with a newline character (), including the last line.
- The lines cannot contain unescaped newline characters, as they would interfere with parsing.
curl -XPOST 'localhost:9200/_bulk?pretty' -H 'Content-Type: application/json' -d'
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} }
{ "doc" : {"title" : "My updated blog post"} }
'The syntactic format is:
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
...
Fortunately, it is easy to find this sweet spot: Try indexing typical documents in batches of increasing size. When performance starts to drop off, your batch size is too big. A good place to start is with batches of 1,000 to 5,000 documents or, if your documents are very large, with even smaller batches.
It is often useful to keep an eye on the physical size of your bulk requests. One thousand 1KB documents is very different from one thousand 1MB documents. A good bulk size to start playing with is around 5-15MB in size
cat
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open logs-live-v2-2017-08-13 WZsOKpLPTqenX94e9bHW1g 5 1 294275045 0 226.1gb 113gb
green open logs-live-v2-2017-08-15 toS_eRpLTjSTya3vY5Ptjw 5 1 223682189 0 169.9gb 84.9gb
green open logs-live-v2-2017-08-16 Cs__a2aARcCVpfzatSk_GA 5 1 217529882 0 167.7gb 83.8gb
green open logs-release-v2-2017-08 59lJiVBASNWmDtmpRrCajw 5 1 1495794 0 1.3gb 728.4mb
green open logs-hotfix-v2-2017-08 sNOe06HQQ9-GwY86AMlOUg 5 1 1920518 0 2.1gb 1gb
green open logs-hotfix-v2-2017-07 medqyWS2RjmHUzrF0mTOjA 5 1 980643 0 484.8mb 242.4mb
green open logs-live-v2-2017-08-18 n5xWNmMNR56lp7aHwulMkA 5 1 114339261 0 89.2gb 45.4gb
green open logs-release-v2-2017-07 YibGjpmfQyakDpKm9ZE6Dg 5 1 187285 0 108.9mb 54.4mb
green open .kibana nqIdvMr_QOe7tLZRcTatzg 1 1 15 1 60.5kb 30.2kb
green open logs-live-v2-2017-08-14 3xFuhX4_TvaeYMEeLgMkCQ 5 1 226026719 0 170.7gb 85.3gb
green open logs-live-v2-2017-08-17 GVqhRMk7TsWB0KjUUqwTQw 5 1 225820075 0 164.4gb 82.2gb
cluster
curl 'http://localhost:9200/_cluster/health'
curl 'http://localhost:9200/_cluster/health?level=indices'
curl 'http://localhost:9200/_cluster/stats'nodes
{
"cluster_name": "elasticsearch_zach",
"nodes": {
"UNr6ZMf5Qk-YCPA_L18BOQ": {
"timestamp": 1408474151742,
"name": "Zach",
"transport_address": "inet[zacharys-air/192.168.1.131:9300]",
"host": "zacharys-air",
"ip": [
"inet[zacharys-air/192.168.1.131:9300]",
"NONE"
],template
curl -XPUT "$ES_ENDPOINT/_template/my-logging" --fail \
-H 'Content-Type: application/json' -d'
{
"template": "logging-*",
"mappings": {
"log": {
"properties": {
"time": {"type": "date"},
"level": {"type": "integer"},
"host": {"type": "string", "index": "not_analyzed"},
"pid": {"type": "string", "index": "not_analyzed"},
"channel": {"type": "string"},
"message": {"type": "string", "analyzer": "whitespace"},
"exc_info": {"type": "string", "analyzer": "whitespace"}
}
}
}
}
'Query string syntax
apple # search "apple" in the default field(which is '_all' by default)
fruit:apple # search "apple" in 'fruit' field
fruit:"pen pineapple" # exact phrase
fruit:(pineapple OR apple)
fruit:(pineapple apple) # Same as above
A AND B OR (NOT C)
A && B || (! C) # Same as above
fruit.\*:apple # fields pattern
_exists_:fruit # where the field has any non-null value
fruit:ap?le # single character wildcard
fruit:apple* # zero or more
fruit:*apple # Don't do this: Leading wildcards are particularly heavy
name:/joh?n/ # regex
quikc~ brwn~ foks~ # fuzzy search (Damerau-Levenshtein distance)
quikc~1 # specific edit distance (default is 2)
"fox quick"~5 # can find "quick fox". 5 is the edit distance by word
count:[1 TO 5] # inclusive (1, 2, 3, 4, 5)
count:{1 TO 5} # exclusive (2, 3, 4)
count:[1 TO 5} # half-open (1, 2, 3, 4)
date:[2016-12-24 TO 2016-12-25]
date:[2016-12-07 TO *] # since 2016-12-07
age:>10
age:>=10
age:<10
age:<=10
quick^2 fox # boost (find 'fox'. but especially interested in "quick fox")
quick +fox -news # +term must be present; -term must not be present; others are optional
((quick AND fox) OR fox) AND NOT news # equivalent to above
# reserved characters (You should escape these characters with '\' if you want to search them literally)
+ - = && || > < ! ( ) { } [ ] ^ " ~ * ? : \ /
Topics
Understanding Cluster
One node in the cluster is elected to be the master node, which is in charge of managing cluster-wide changes like creating or deleting an index, or adding or removing a node from the cluster. The master node does not need to be involved in document-level changes or searches, which means that having just one master node will not become a bottleneck as traffic grows. Any node can become the master. Our example cluster has only one node, so it performs the master role.
Inside a Shard
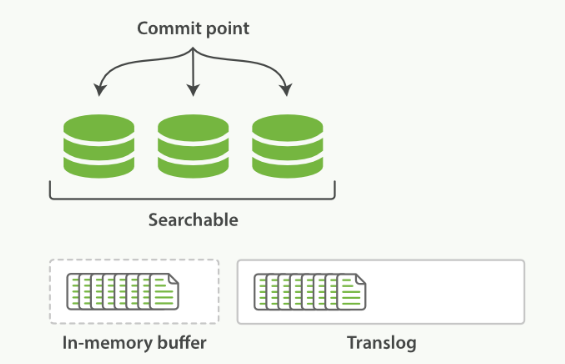
- A shard is a low-level worker unit that holds just a slice of all the data in the index.
- a single instance of Lucene, and is a complete search engine in its own right.
- a Lucene index is what we call a shard in Elasticsearch, while an index in Elasticsearch is a collection of shards.
- The inverted index that is written to disk is immutable
- Dynamically Updatable Indices
- When a document is “deleted,” it is actually just marked as deleted in the .del file. A document that has been marked as deleted can still match a query, but it is removed from the results list before the final query results are returned.
- Making Changes Persistent
- The translog provides a persistent record of all operations that have not yet been flushed to disk
- The action of performing a commit and truncating the translog is known in Elasticsearch as a flush.
- Small segments are merged into bigger segments, which, in turn, are merged into even bigger segments.
Routing a Document to a Shard
shard = hash(routing) % number_of_primary_shards
This explains why the number of primary shards can be set only when an index is created and never changed
Choosing Number of Shards
A Shard is not free
- A shard is a Lucene index under the covers, which uses file handles, memory, and CPU cycles.
- Every search request needs to hit a copy of every shard in the index. That’s fine if every shard is sitting on a different node, but not if many shards have to compete for the same resources.
- Term statistics, used to calculate relevance, are per shard. Having a small amount of data in many shards leads to poor relevance.
Searching 1 index of 50 shards is exactly equivalent to searching 50 indices with 1 shard each: both search requests hit 50 shards.
Routing
The routing value defaults to the document’s
_id, but we can override that and provide our own custom routing value, such asforum_id.
PUT /forums/post/1?routing=baking
{
"forum_id": "baking",
"title": "Easy recipe for ginger nuts",
...
}
Inverted Index
Term | Doc 1 | Doc 2 | Doc 3 | ...
------------------------------------
brown | X | | X | ...
fox | X | X | X | ...
quick | X | X | | ...
the | X | | X | ...
Terms are normalized
Quickcan be lowercased to becomequick.foxescan be stemmed–reduced to its root formto becomefox.- Similarly,
dogscould be stemmed todog. jumpedandleap are synonyms and can be indexed as just the single termjump.
This is very important. You can find only terms that exist in your index, so both the indexed text and the query string must be normalized into the same form.
This process of tokenization and normalization is called analysis.
Analysis and Analyzers
- Tokenizing a block of text into individual terms suitable for use in an inverted index
- Normalizing these terms into a standard form to improve their searchability or recall
Kinds of analyzers
Standard
set, the, shape, to, semi, transparent, by, calling, set_trans, 5~Simple
set, the, shape, to, semi, transparent, by, calling, set, transWhitespace
Set, the, shape, to, semi-transparent, by, calling, set_trans(5)Language analyzers
set, shape, semi, transpar, call, set_tran, 5 (english)
Mappings for Configuring Analyzers
Although you can add to an existing mapping, you can’t change existing field mappings. If a mapping already exists for a field, data from that field has probably been indexed. If you were to change the field mapping, the indexed data would be wrong and would not be properly searchable.
How Inner(Nested) Objects are Indexed
Inner objects
Array of Inner objects
{ "followers.age": [19, 26, 35], "followers.name": ["alex", "jones", "lisa", "smith", "mary", "white"] }In this way, the relation between
ageandnameis lost. To work around this, set the type offollowersto nested.
How Queries Work
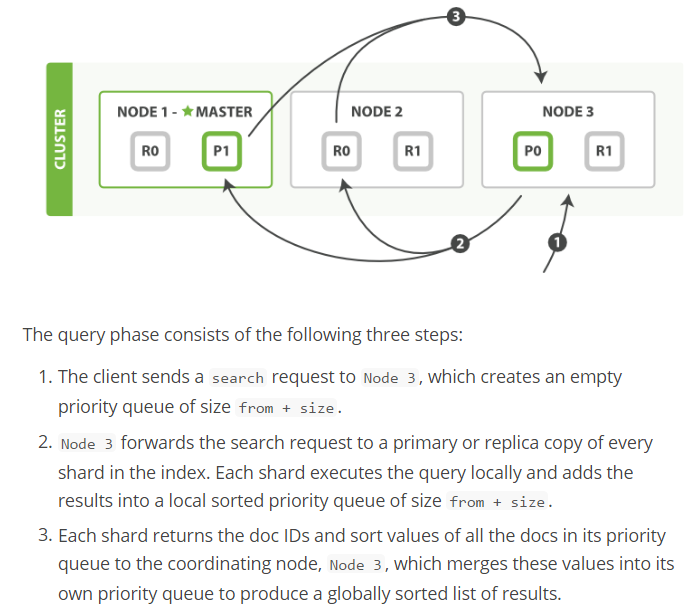
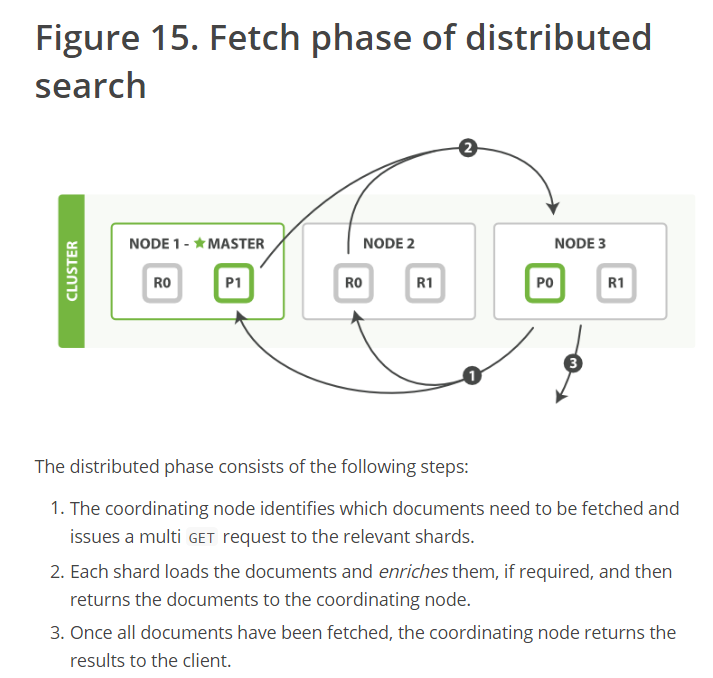
- https://www.elastic.co/guide/en/elasticsearch/guide/current/_query_phase.html
- https://www.elastic.co/guide/en/elasticsearch/guide/current/_fetch_phase.html
Types and Mappings
what happens if you have two different types, each with an identically named field but mapped differently (e.g. one is a string, the other is a number)?
The longer answer is that each Lucene index contains a single, flat schema for all fields. A particular field is either mapped as a string, or a number, but not both.
_allfield: a special field that indexes the values from all other fields as one big string. The querystring query clause (and searches performed as?q=john) defaults to searching in the_allfield if no other field is specified.- When Elasticsearch encounters a previously unknown field in a document, it uses dynamic mapping to determine the datatype for the field and automatically adds the new field to the type mapping.
How-to
Configure Settings and Deployment
- Revisit This List Before Production
- https://www.elastic.co/guide/en/elasticsearch/guide/current/hardware.html
- https://www.elastic.co/guide/en/elasticsearch/guide/current/_java_virtual_machine.html
- https://www.elastic.co/guide/en/elasticsearch/guide/current/important-configuration-changes.html
Please Do Not Tweak JVM Settings
If you have two masters, data integrity becomes perilous, since you have two nodes that think they are in charge.
A quorum is (number of master-eligible nodes / 2) + 1.
Manage the change of mappings
- Don't follw this way manually. There is a Reindex API.
There seems to be a conflict between the use case of index templates and index aliases.
My personal workaround is using index templates with versioning like REST APIs. ex) myindex-v1-2017-08-15, myindex-v2-2017-08-16, etc.
In this way, you can query for common fields across indexes even if the mapping has been changed through index wildcard queries.